速通线段树(入门)
2023年3月15日第6次修订
本内容必要条件:
- 看懂代码的必要条件:c++的基本语法(数组、函数调用、结构体、输入输出)
- 掌握逻辑的必要条件:掌握递归算法思想(不会的我无法保证你能看懂)
warning-警告!!! warning-警告!!! warning-警告!!!
(一)如果你没有了解过递归,我无法保证你能完全看懂本文。如果你执意学习,请做好可能失败的心理准备。
(二)如果你没有学过C++基本语法(但是学过其他语言,也了解过递归),请翻阅下去,本文不会让你后悔。作者也是JAVA出身。作者保证你可以看懂除代码外的其它内容。
如果你没有了解过递归,请至少学习斐波那契数列的递归实现或汉诺塔的递归(或者其它简单递归)的实现后再来观看!谢谢您的配合!
如果你没有了解过递归,请至少学习斐波那契数列的递归实现或汉诺塔的递归(或者其它简单递归)的实现后再来观看!谢谢您的配合!
如果你没有了解过递归,请至少学习斐波那契数列的递归实现或汉诺塔的递归(或者其它简单递归)的实现后再来观看!谢谢您的配合!
非必要条件:
- 会堆(Heap)这个数据结构(可以帮助你更快速入门)
读者若是不会堆,作者也保证你可以看懂线段树
0.观前提醒:递归和堆结构是递归且非动态开点的线段树的必要组成
本文只教授递归式且非动态开点的线段树
- 递归式线段树
- 堆(Heap)式的、且空间以及开辟完成的、采用数组模拟内存的线段树
如果你不会堆,本文可以保证你可以看懂。
1.(重点)抓住线段树的精髓:维护区间信息
- 线段树是一个数据结构
- 区间信息:数据离散化(数据索引是有限的)成一条直线(数组),上面截出一段(数组的一部分)的信息(区间和,区间平方差和,最大最小值,异或值……)
- 维护:如果你改了上面的一些数据,它仍然可以帮你查询出来
请仔细理解维护区间信息这个内容,并牢记于心,仔细体会
2.如何实现维护区间信息(思想)
2.1.线段树的结构
观前提醒:如果你是新手,在看这一节(2.1节)的时候,请你把大脑中“这个用代码怎么实现?”这种问题清除掉,我们只关注结构本身。
请牢记:开始的时候,走的稳、走的慢,最后才能走的远。
假设我们有以下的区间信息(下标从1到8一共8个内容),内容是随便取的不用纠结,因为下面用不到它

线段树的做法利用分而治之的思想,将1-8的区间信息放入一个格子中,然后将其分成两段(其实是有多段实现的,但是我们只学习最基础的两段式)
我们将顶点1-4和5-8的区间信息分开存储,周而复始,依次往下
1-4分成1-2和3-4,5-8分成5-6和7-8,以此类推
如果你无法理解什么是区间信息的话,你可以举例(假装)为这些格子的数字之和(假装现在区间信息就是这些数字之和)
其实区间信息有很多种,我在第一节中就列出来了一些(区间和,区间平方差和,最大最小值,异或值……)
(如果你没有好好看,请你回过去再仔细体会一下维护区间信息这个精髓说法)
一图胜千言:

你可能非常容易就发现了最底下的格子颜色与上面的不一样,因为他们是最小区间单位(也就是只存储一个格子的信息,所谓的2-2就是2到2,那就是2这个格子本身)。
那么到此为止,读者肯定发现了一个问题:为什么我刚好选的是8,刚好是2的幂次?原因是这样好画,但是这不是问题的答案。
因为我们必须也应该知道,不是2的倍数,不是2的幂次时线段树该如何建立
譬如1到7时,我们该怎么建立呢?一般是向下取整建立分段(即7整除2答案为3,你可以理解为把余数全部去除)
区间1-3分成1-2和1-1,区间4-7分成4-5和6-7(4加7是11,11整除2是5,所以以5位分界点)
所以这样建立的图如下所示:

2.1练习:绘画1-11的线段树
大家可以在纸上自己绘画1-11的线段树区间信息段,然后与我的数据对照,重点关注绿色的最小区间单位节点是什么地方

至此为止,其实你已经学了一半的线段树了,也就是线段树的数据存储方式(怎么画出线段树,每个格子是什么意思)
作者这里想说一些话:
假设不涉及代码,我们也可以画出线段树的格子,不是吗?
代码固然重要,但是思路在其中占比至少也是50%
如果你是初学者,画出了格子,那么你已经成功百分之50了。有些东西没有想象的那么难。
2.2.核心思想一:儿子与父亲的关系
从2.2开始,我们慢慢铺垫如何用代码实现,稍安勿躁。(也不会出现很多代码)
如果你没有学过二叉树(Binary-Tree)和堆(Heap),那么可以仔细看看下面的内容。
儿子和父亲是相对关系,上面的是父亲,下面的是儿子。树上的每一个格子我们称为结点
请注意:儿子和父亲是一层之内的相对关系,儿子分左右,父亲只有一个,请对照下面的图进行理解



(重点)堆(Heap)的结点编号系统
我们接下来要干一个非常重要的事情:对每个结点进行编号,也是堆的核心思想。

请仔细观察每个儿子与父亲编号的关系!!
我们可以得出以下结论:
- 所有的左儿子的编号是它父亲编号的两倍
- 所有的右儿子的编号是它父亲编号的两倍加一
- 所有的父亲的编号是任意一个儿子的编号整除二
- 先从左往右,再从上往下,我们可以发现编号刚好是顺序的1到16
1到3毋庸置疑,4可以得出一个非常爆炸的结论:
- 我们可以将这颗树按照顺序存入一个数组中。
- 存入数组后,这棵树的父亲和儿子关系可以通过编号的乘法和除法得到
聪明的读者肯定发现了一个问题:你这不对啊,那我刚刚1-11的那颗树不是还有空着的地方吗,那怎么存?
我的回答是:建立空节点,缺多少,塞多少,全部塞满,直接塞成$ 2^n - 1$个结点就行了,(NULL就是空节点)

本节核心:成功使用数组的形式解决了存储树的问题。
2.3.核心思想二:递归建立(build)线段树
递归的本质是:函数的自调用
这里想问问大家:函数自调用的核心是什么?
我的回答是:递归出口(即停止递归的条件)。一个递归如果没有出口,那么它会无限调用自己,然后爆栈(Stack Overflow)
函数自调用的秘诀是什么?
build() {
---------- if() return;
-----递归出口可以出现在拿资源之前的任何地方,但是必须出现,否则无法停止。可以有多个递归出口
操作已经有的资源
====调用前====
----让我的儿子(下属,奴仆)去拿资源
build()
====调用后====
----这个时候已经拿到了想要的资源了
整合资源
}- 操作已经有的资源,做准备工作(调用前)
- 找到还缺少的资源,让我的儿子去拿资源(调用函数Call)
- 儿子拿到我要的资源,我就整合所有资源(调用后)
以线段1-8为例,向大家展示整个调用过程
使用《》来代表图中的箭头,使用【】代表图中的结点,重要位置我会用下划线标注
《箭头1》调用函数Build()
- 【1号点】:我没有区间1到8的信息
《箭头2》【1号点】:调用函数Build(),指向【2号点】
- 【2号点】我没有区间1到4的信息
《箭头3》【2号点】:调用函数Build(),指向【4号点】
- 【4号点】我没有区间1到2的信息
《箭头4》【4号点】:调用函数Build(),指向【8号点】
- 【8号点】:我拥有区间1到1的信息!!,退出递归,存储数据给【4号点】!
《箭头5》【4号点】:调用函数Build(),指向【9号点】
- 【9号点】:我拥有区间2到2的信息!!,退出递归,存储数据给【4号点】!
- 【4号点】:我拥有了区间1到2的信息!!退出递归,存储数据给【2号点】!
《箭头6》【2号点】:调用函数Build(),指向【5号点】
- 【5号点】:我没有区间3到4的信息
《箭头7》【5号点】:调用函数Build(),指向【10号点】
- 【10号点】:我拥有区间3到3的信息!!,退出递归,存储数据给【5号点】!
《箭头8》【5号点】:调用函数Build(),指向【11号点】
- 【11号点】:我拥有区间4到4的信息!!,退出递归,存储数据给【5号点】!
- 【5号点】:我拥有了区间3到4的信息!!退出递归,存储数据给【2号点】!
- 【2号点】:我拥有了区间5到8的信息!!退出递归,存储数据给【1号点】!
《箭头9》【1号点】:调用函数Build(),指向【3号点】
【3号点】:我没有区间5到8的信息
- ----------过程略…………………………
- 【3号点】:我拥有了区间5到8的信息!!退出递归,存储数据给【1号点】!
- 【1号点】:我已经有区间1到8的信息了!退出递归!完成最终函数!
线段树建立完成!!!!
线段树建立完成!!!!
线段树建立完成!!!!

粗略计算一下建立线段树需要多少时间复杂度
假设数据量是N,假设所有叶子结点(最底下这层区间只有自己的点)都充满,最多的时间也不过2N(满二叉树的叶子结点是所有结点数量的一半+1,所以剩余的结点数不会超过叶子结点)
所以建立线段树是线性复杂度O(N),虽然是递归实现的
2.4.核心思想三:递归修改(modify)线段树
我们知道,线段树的核心是维护区间信息,刚才我们已经初始化了区间信息,是否能用原来的方法实现修改呢?
正所谓天上没有掉下来的馅饼,世界上哪有这么好的事情呢?
假设我们要修改区间4-7(譬如每一个点上都加上3),那么紫色结点就是我们最终要到达的地方,蓝色结点是走过的地方。
你会发现一个严重的问题:我这要跑的次数也太多了吧
如果在大量的修改下,每一次都是近乎N的数据量。假设有M次修改,我的时间复杂度就约等于N*M
如果是10000的数据量和10000次查询,那就是1亿的数据量!!(一般100万数据需要0.1s(0.1秒),1000万就是1s(秒))
只有10000的数据量就导致了时间近乎10秒以上,这是令人无法接受的,所以要引出线段树的核心中的核心

最最最重点部分:懒加载(lazy-load)
其实用一句话概括这个神奇的算法就是:用的时候才给你,不用的时候就欺上瞒下
什么意思呢?什么叫做懒加载呢?
假设我们要修改区间信息5-8(比如每个都加上3)
此时递归进行到5-8,你会发现整个区间都落在了5-8,那么我们修改完后递归上去,让1-8这个节点也修改

也就是说此时你只有【区间信息5-8】和【区间信息1-8】是被修改的。然后你给【区间信息5-6】【区间信息7-8】打个标记,告诉他们这次我每个点加了多少,让他们记好。这个标签就是lazytag(你想叫啥都行啦,只是个名字,你叫他dog也没事)。
也就是【区间信息5-8】欺上瞒下(其实没有瞒下)完成了修改。

对于懒标记我们必须要了解这几个事实
- 拥有懒标记的结点说明此前并没有查询到,需要激活懒标记来获得正确数据(如果这个操作不一样,那么代码也就不一样,有多种解释。可以跳转第四节观看详细解释。)
- 激活懒标记后,应该将懒标记下放到两个儿子结点,儿子结点不会修改,只是添加了懒标记
- 激活懒标记后,数据更改,懒标记归回初始值(每个算法不一样,如果是加和,那么初始是0)
拥有了懒加载后,我们需要激活(active)懒标记。
如何激活懒标记
接下来演示的两种情况是:父亲节点没有懒标记和原来已经有懒标记的两种情况
首先看父节点的lazytag是初始值的情况


接下来看看父节点本来就已经有lazytag的情况


如何寻找区间并执行
这里还有一个更加重要的问题,那就是如何寻找区间:哪些区间要打上标记,哪些区间是被查找到后就欺上瞒下直接返回消息的
首先我们先给出最终结果:
假设我们要查找4-7的时候,区间信息3-4 区间信息5-6 区间信息7-7这三块(红色部分)的就是最终欺上瞒下的部分
他们的左右子树(黄色部分)就是打上懒标记的部分

看到这个结果以后,我们必须要模拟出来具体寻找过程
设我们修改的区间是L到R(如果是4到7,那么L就是4,R就是7)
修改(modify)函数请严格遵循以下原则:
无论如何,先判断自身是否拥有懒标记
- 激活自己的懒标记,因为只有这样自己的值才是正确的
- 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
- 初始化自身懒标记,回归原始状态
- 当前的区间信息范围完全不在L到R之内时,我们直接返回(return)
当前的区间信息范围完全在L到R之内时
- 将自己的值直接修改完成
- 将左右子树的懒标记改为自己需要修改的值
- 返回(return)
- 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
- 读取左右子树已经更新过的信息,将自身信息更新,因为只有被查到的会有被修改,而父亲节点不会被修改
关于2的说明:怎么样保证当前的区间信息范围完全不在L到R之内?
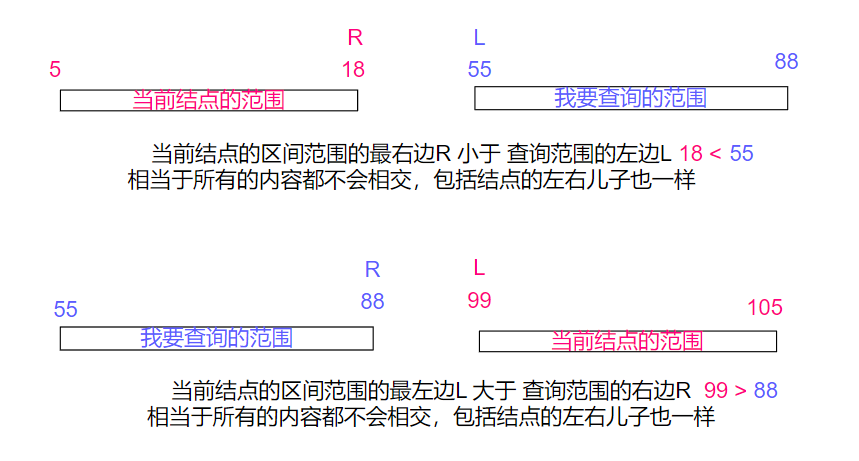
【对于原则5的示意图片】:这些没有被修改的信息必须在子树修改完后,递归回去的路上被修复。

2.5.核心思想四:递归查找(query)线段树
其实递归查找的步骤就是递归修改的稍微改版而已。只是有一些些的不一样。这里我们直接给出递归查找的原则
查询(query)函数请严格遵循以下原则:
无论如何,先判断自身是否拥有懒标记
- 激活自己的懒标记,因为只有这样自己的值才是正确的
- 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
- 初始化自身懒标记,回归原始状态
- 当前的区间信息范围完全不在L到R之内时,我们直接返回初始值(每个题不一样,如果是求和就返回0)(return 初始值)
- 当前的区间信息范围完全在L到R之内时,我们直接返回这个结点的值(return 结点值)
- 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下),并将其返回的内容进行处理
请注意:我们这里不需要进行修改中的第5步:自身信息更新,因为查询的时候不会修改,那么原来的值就已经是最终值了,我们只需要激活懒标记就行了。
而存在着lazytag值的父亲已经被变过了,否则这个结点也不可能有lazytag(它的lazytag是父亲给的,那么父亲已经被修改过了,是最终值了)
请仔细理解以下的话,与修改的部分进行仔细对比,必须理解清楚再进入第三章
- 存在着lazytag值的父亲已经被变过了
- 激活懒标记只是为了让它回到正确的值,而不是它现在会被改变,是它曾经已经被改变过了
- 别忘了激活懒标记后下放到左右子树
还是以查询4-7为例,我们只需要激活lazytag和下放lazytag然后返回即可。

3.如何用C++实现线段树(代码)
3.1.线段树的结构体实现
这里我使用了结构体,但是这个结构体完全可以拆成4个数组使用。
使用结构体的目的是为了让思路更加清楚,将每一个线段树的结点封装成一个结构体类型抽象化,能更加容易写出代码
线段树的每个结点至少包含四个东西
- 区间信息的左起始点
- 区间信息的右起始点
- 当前结点的值
- 当前结点的懒标记
而且这样的结点是批量建立的数组形式(堆的形式)
由于我们不用维护左右子树和父亲的关系(因为我们采用了堆的建法),所以不需要在结点内写明关系。
我们只需要建立足够大的堆(数组)将结点依次存入即可,数组之间的下标就是他们之间的关系
所以我们可以写出这样的结构体:
struct Tree{
左起始点 l
右起始点 r
值 ans
懒标记 lazy
}数组名[数组大小];这里给出我的例子(以洛谷P3372 【模板】线段树 1为例)
typedef long long LL; //将long long 类型定义为LL,后面使用LL就是使用long long 长整型
const int N = 2e5 + 10; //定义只读整型int,2e5是科学计数法 代表2 * 10^5,也就是20万。 最后加上5 就是 200005
struct Tree{
int l, r;
LL ans, lazy;
}tr[N << 2]; //N<<2 代表N位运算左移两位, 代表N乘以4
//tr代表结构体数组,存储树的每个结点信息,下标以1开始。
LL e[N << 2]; // 这里e存储的是原本的数据,下标以1开始。3.2.线段树的初始化建立
假设我们的函数是build
void build(结点下标 x, 当前结点的左起始点 l, 当前结点的右起始点r) {
tr[x].l = l; tr[x].r = l; //这一步是在利用递归函数初始化线段树每个结点的左右起始点(区间信息)
if(l == r) { //当l==r的时候,说明这个结点已经到头了。区间只有一格这么大,所以我们存储值然后返回
存储tr[x]的值;
return;
}
mid = (l + r) / 2; //找出当前结点的中间值,区分左右
build(x * 2, l, mid); //向左节点查询,范围是【l,mid】
build(x * 2 + 1, mid + 1, r); //向右节点查询,范围是【mid+1,r】
tr[x]的值 整合为 tr[x]左节点的值 与 tr[x]右节点的值的信息
}这里给出我的例子(以洛谷P3372 【模板】线段树 1为例)
这里请注意:e[l]代表到了叶子结点时,它的左右起始点就代表了原数组的位置。(可以观察一下起始点和原数据的关系)
void build(int x, int l, int r) {
tr[x].l = l;
tr[x].r = r;
if(l == r) {
tr[x].ans = e[l]; // 这里e存储的是原本的数据的数组。e[l]代表到了叶子结点时,它的左右起始点就代表了原数组的位置。
return;
}
int mid = (l + r) >> 1; // >>1 就是右移一位,位运算。相当于除以2
build(x << 1, l, mid); // << 1 就是左移一位,位运算。相当于乘以2
build(x << 1 | 1, mid + 1, r); // << 1 | 1 就是左移一位然后和1进行与运算,位运算。相当于乘以2加1
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans; //这里是整合左右节点信息之和,因为题目就是信息之和
}3.3.线段树的修改
修改(modify)函数请严格遵循以下原则:
无论如何,先判断自身是否拥有懒标记
- 激活自己的懒标记,因为只有这样自己的值才是正确的
- 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
- 初始化自身懒标记,回归原始状态
- 当前的区间信息范围完全不在L到R之内时,我们直接返回(return)
当前的区间信息范围完全在L到R之内时
- 将自己的值直接修改完成
- 将左右子树的懒标记改为自己需要修改的值
- 返回(return)
- 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
- 读取左右子树已经更新过的信息,将自身信息更新,因为只有被查到的会有被修改,而父亲节点不会被修改
void modify(结点下标 x, 要修改的位置左起始点 l, 要修改的位置右起始点 r, 要修改的数据 k) {
if(tr[x] 有懒标记) {
1. 激活自己的懒标记,因为只有这样自己的值才是正确的
2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
3. 初始化自身懒标记,回归原始状态
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回
if(tr[x].l > r || tr[x].r < l) return;
// 当前的区间信息范围完全在L到R之内时
if(tr[x].l >= l && tr[x].r <= r) {
1. 将自己的值 直接修改完成
2. 将左右子树的懒标记改为 自己需要修改的值
return;
}
//当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
modify(x * 2, l, r, k); //向左节点查询
modify(x * 2 + 1, l, r, k); //向右节点查询
//读取左右子树已经更新过的信息,将自身信息更新
tr[x]的值 整合为 tr[x]左节点的值 与 tr[x]右节点的值的信息
}这里给出我的例子(以洛谷P3372 【模板】线段树 1为例)
对于(tr[x].l > r || tr[x].r < l) 这个内容的解释,看下图所示
void modify(int x, int l, int r, LL k) {
if(tr[x].lazy) {
//1. 激活自己的懒标记,因为只有这样自己的值才是正确的
tr[x].ans += (tr[x].r - tr[x].l + 1) * tr[x].lazy;
//2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
//3. 初始化自身懒标记,回归原始状态
tr[x].lazy = 0;
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回
// 这个内容可以直接看上图所示
if(tr[x].l > r || tr[x].r < l) return;
// 当前的区间信息范围完全在L到R之内时
if(tr[x].l >= l && tr[x].r <= r) {
//1. 将自己的值 直接修改完成
tr[x].ans += (tr[x].r - tr[x].l + 1) * k;
// 2. 将左右子树的懒标记改为 自己需要修改的值
tr[x << 1].lazy += k;
tr[x << 1 | 1].lazy += k;
return;
}
//当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
modify(x << 1, l, r, k);
modify(x << 1 | 1, l, r, k);
//读取左右子树已经更新过的信息,将自身信息更新
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}3.4.线段树的查询
查询(query)函数请严格遵循以下原则:
无论如何,先判断自身是否拥有懒标记
- 激活自己的懒标记,因为只有这样自己的值才是正确的
- 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
- 初始化自身懒标记,回归原始状态
- 当前的区间信息范围完全不在L到R之内时,我们直接返回初始值(每个题不一样,如果是求和就返回0)(return 初始值)
- 当前的区间信息范围完全在L到R之内时,我们直接返回这个结点的值(return 结点值)
- 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下),并将其返回的内容进行处理
返回值 query(结点下标 x, 要查询的位置左起始点 l, 要查询的位置右起始点 r) {
if(tr[x] 有懒标记) {
1. 激活自己的懒标记,因为只有这样自己的值才是正确的
2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
3. 初始化自身懒标记,回归原始状态
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回初始值(每个题不一样,如果是求和就返回0)(return 初始值)
if(tr[x].l > r || tr[x].r < l) return 初始值;
// 当前的区间信息范围完全在L到R之内时,我们直接返回这个结点的值
if(tr[x].l >= l && tr[x].r <= r) return 结点值;
// 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
// 并将其返回的内容进行处理
}这里给出我的例子(以洛谷P3372 【模板】线段树 1为例)
LL query(int x, int l, int r) {
LL ans = 0; //这就是处理值的内容,每个题目都不一样
if(tr[x].lazy) {
// 1. 激活自己的懒标记,因为只有这样自己的值才是正确的
tr[x].ans += (tr[x].r - tr[x].l + 1) * tr[x].lazy;
// 2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
// 3. 初始化自身懒标记,回归原始状态
tr[x].lazy = 0;
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回初始值(每个题不一样,如果是求和就返回0)(return 初始值)
if(tr[x].l > r || tr[x].r < l) return 0;
// 当前的区间信息范围完全在L到R之内时,我们直接返回这个结点的值
if(tr[x].l >= l && tr[x].r <= r) return tr[x].ans;
// 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
// 并将其返回的内容进行处理
ans += query(x << 1, l, r);
ans += query(x << 1 | 1, l, r);
return ans;
}3.5.【例题1】洛谷P3372 【模板】线段树 1
链接在下方:
P3372 【模板】线段树 1 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
题目描述
如题,已知一个数列,你需要进行下面两种操作:
- 将某区间每一个数加上 $k$。
- 求出某区间每一个数的和。
输入格式
第一行包含两个整数 $n, m$,分别表示该数列数字的个数和操作的总个数。
第二行包含 $n$ 个用空格分隔的整数,其中第 $i$ 个数字表示数列第 $i$ 项的初始值。
接下来 $m$ 行每行包含 $3$ 或 $4$ 个整数,表示一个操作,具体如下:
1 x y k:将区间 $[x, y]$ 内每个数加上 $k$。2 x y:输出区间 $[x, y]$ 内每个数的和。
输出格式
输出包含若干行整数,即为所有操作 2 的结果。
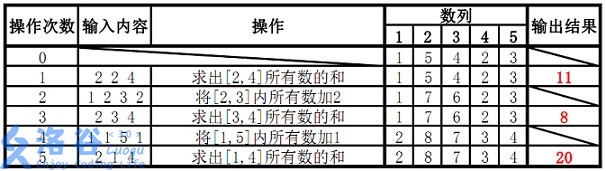
样例 #1
样例输入 #1
5 5
1 5 4 2 3
2 2 4
1 2 3 2
2 3 4
1 1 5 1
2 1 4样例输出 #1
11
8
20提示
对于 $30\%$ 的数据:$n \le 8$,$m \le 10$。
对于 $70\%$ 的数据:$n \le {10}^3$,$m \le {10}^4$。
对于 $100\%$ 的数据:$1 \le n, m \le {10}^5$。
保证任意时刻数列中所有元素的绝对值之和 $\le {10}^{18}$。
【样例解释】
【例题1】题目解析与代码
对于此题,我使用的懒标记激活方法与之前相同
我的代码如下:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL; //将long long 类型定义为LL,后面使用LL就是使用long long 长整型
const int N = 2e5 + 10; //定义只读整型int,2e5是科学计数法 代表2 * 10^5,也就是20万。 最后加上5 就是 200005
struct Tree{
int l, r;
LL ans, lazy;
}tr[N << 2]; //N<<2 代表N位运算左移两位, 代表N乘以4
//tr代表结构体数组,存储树的每个结点信息,下标以1开始。
LL e[N << 2]; // 这里e存储的是原本的数据,下标以1开始。
void build(int x, int l, int r) {
tr[x].l = l;
tr[x].r = r;
if(l == r) {
tr[x].ans = e[l]; // 这里e存储的是原本的数据的数组。e[l]代表到了叶子结点时,它的左右起始点就代表了原数组的位置。
return;
}
int mid = (l + r) >> 1; // >>1 就是右移一位,位运算。相当于除以2
build(x << 1, l, mid); // << 1 就是左移一位,位运算。相当于乘以2
build(x << 1 | 1, mid + 1, r); // << 1 | 1 就是左移一位然后和1进行与运算,位运算。相当于乘以2加1
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans; //这里是整合左右节点信息之和,因为题目就是信息之和
}
void modify(int x, int l, int r, LL k) {
if(tr[x].lazy) {
//1. 激活自己的懒标记,因为只有这样自己的值才是正确的
tr[x].ans += (tr[x].r - tr[x].l + 1) * tr[x].lazy;
//2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
//3. 初始化自身懒标记,回归原始状态
tr[x].lazy = 0;
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回
// 这个内容可以直接看上图所示
if(tr[x].l > r || tr[x].r < l) return;
// 当前的区间信息范围完全在L到R之内时
if(tr[x].l >= l && tr[x].r <= r) {
//1. 将自己的值 直接修改完成
tr[x].ans += (tr[x].r - tr[x].l + 1) * k;
// 2. 将左右子树的懒标记改为 自己需要修改的值
tr[x << 1].lazy += k;
tr[x << 1 | 1].lazy += k;
return;
}
//当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
modify(x << 1, l, r, k);
modify(x << 1 | 1, l, r, k);
//读取左右子树已经更新过的信息,将自身信息更新
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}
LL query(int x, int l, int r) {
LL ans = 0; //这就是处理值的内容,每个题目都不一样
if(tr[x].lazy) {
// 1. 激活自己的懒标记,因为只有这样自己的值才是正确的
tr[x].ans += (tr[x].r - tr[x].l + 1) * tr[x].lazy;
// 2. 将自己的懒标记下发左右子树,让他们获得自己当前懒标记
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
// 3. 初始化自身懒标记,回归原始状态
tr[x].lazy = 0;
}
// 当前的区间信息范围完全不在L到R之内时,我们直接返回初始值(每个题不一样,如果是求和就返回0)(return 初始值)
if(tr[x].l > r || tr[x].r < l) return 0;
// 当前的区间信息范围完全在L到R之内时,我们直接返回这个结点的值
if(tr[x].l >= l && tr[x].r <= r) return tr[x].ans;
// 当前的区间信息范围部分落在L到R之内时,继续搜索左右子树(调用函数递归向下)
// 并将其返回的内容进行处理
ans += query(x << 1, l, r);
ans += query(x << 1 | 1, l, r);
return ans;
}
int main() {
int n, m;
cin >> n >> m;
//读入初始数据量
for(int i = 1; i <= n; i++) {
scanf("%lld", &e[i]);
}
//建立线段树
build(1, 1, n);
while(m--) {
int a, b, d; LL c;
scanf("%d", &d);
if(d == 2) {
//查询
scanf("%d%d", &a, &b);
printf("%lld\n", query(1, a, b));
} else {
//修改
scanf("%d%d%lld", &a, &b, &c);
modify(1, a, b, c);
}
}
return 0;
}4.关于懒标记Lazy-tag不同种类的写法
2023年3月14日修订:
两个方法都可以使用,方法二是市面上(包括洛谷中)一直都使用的方法,而作者的方法是方法一,大家按需使用
由于方法二市面上给出的比较多,我在后面的例题中就不再重复给出了。
我的方法主要有以下特性
- 拥有懒标记的结点说明此前并没有查询到,需要激活懒标记来获得正确数据
- 激活懒标记后,应该将懒标记下放到两个儿子结点,儿子结点不会修改,只是添加了懒标记
- 激活懒标记后,数据更改,懒标记归回初始值
但是目前许多代码中的操作是这样的:
- 拥有懒标记的结点说明此前已经被查询到了,且已经获得了正确的数据
- 查询到懒标记时,需要对儿子结点进行修改,并且下放懒标记,然后将懒标记回归初始值
- 激活懒标记后,数据不会更改(因为以前就更改过了),懒标记归回初始值
关键点在于拥有懒标记的节点是否已经被修改过。
文中给出的是《到了以后再加载》 这种比较符合逻辑的解法
而《标记有了就已经被修改过了》注重的是标记只是用来下放,下放的时候就应该把儿子结点修改完成了
但是方法二有个优点:由于到了这个标记时,它已经被修改过了,所以可以放在函数出口的后面,而不造成影响
具体看下列函数对比:
//这是方法二的函数
//有懒标记的,说明它是已经被加过的数据.
void modify(int x, int l, int r, LL k) {
if(tr[x].l > r || tr[x].r < l) return;
// ==================注意这里的细节(1)=================
// 懒加载被激活可以放在函数返回之后,因为懒标记被放上去的时候就已经被修改了
// 懒标记只会激活儿子结点,而自己只是作为下放工具
if(tr[x].lazy) {
tr[x << 1].ans += (tr[x << 1].r - tr[x << 1].l + 1) * tr[x].lazy;
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].ans += (tr[x << 1 | 1].r - tr[x << 1 | 1].l + 1) * tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
tr[x].lazy = 0;
}
if(tr[x].l >= l && tr[x].r <= r) {
tr[x].ans += (tr[x].r - tr[x].l + 1) * k;
// ==================注意这里的细节(2)=================
// 懒标记只加载自己的结点
tr[x].lazy += k;
return;
}
modify(x << 1, l, r, k);
modify(x << 1 | 1, l, r, k);
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}
//这是方法一的函数
//有懒标记的,说明它是未初始化的函数
void modify(int x, int l, int r, LL k) {
// ==================注意这里的细节(1)=================
// 懒加载被激活必须放在函数返回之前,因为这样才能保证每个点是最新的
// 懒标记只会激活自己,儿子结点只会下放
if(tr[x].lazy) {
tr[x].ans += (tr[x].r - tr[x].l + 1) * tr[x].lazy;
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
tr[x].lazy = 0;
}
if(tr[x].l > r || tr[x].r < l) return;
if(tr[x].l >= l && tr[x].r <= r) {
tr[x].ans += (tr[x].r - tr[x].l + 1) * k;
// ==================注意这里的细节(2)=================
// 懒标记只加载儿子结点
tr[x << 1].lazy += k;
tr[x << 1 | 1].lazy += k;
return;
}
modify(x << 1, l, r, k);
modify(x << 1 | 1, l, r, k);
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}具体的通过代码贴在下放供大家研究
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 2e5 + 10;
struct Tree{
LL ans;
int l, r;
LL lazy;
}tr[N << 2];
LL e[N << 2];
void build(int x, int l, int r) {
tr[x].l = l;
tr[x].r = r;
if(l == r) {tr[x].ans = e[l]; return;}
int mid = (l + r) >> 1;
build(x << 1, l, mid);
build(x << 1 | 1, mid + 1, r);
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}
//有懒标记的,说明它是已经被加过的数据.
void modify(int x, int l, int r, LL k) {
if(tr[x].l > r || tr[x].r < l) return;
if(tr[x].lazy) {
tr[x << 1].ans += (tr[x << 1].r - tr[x << 1].l + 1) * tr[x].lazy;
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].ans += (tr[x << 1 | 1].r - tr[x << 1 | 1].l + 1) * tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
tr[x].lazy = 0;
}
if(tr[x].l >= l && tr[x].r <= r) {
tr[x].ans += (tr[x].r - tr[x].l + 1) * k;
tr[x].lazy += k;
return;
}
modify(x << 1, l, r, k);
modify(x << 1 | 1, l, r, k);
tr[x].ans = tr[x << 1].ans + tr[x << 1 | 1].ans;
}
LL query(int x, int l, int r) {
LL ans = 0;
if(tr[x].l > r || tr[x].r < l) return 0;
if(tr[x].lazy) {
tr[x << 1].ans += (tr[x << 1].r - tr[x << 1].l + 1) * tr[x].lazy;
tr[x << 1].lazy += tr[x].lazy;
tr[x << 1 | 1].ans += (tr[x << 1 | 1].r - tr[x << 1 | 1].l + 1) * tr[x].lazy;
tr[x << 1 | 1].lazy += tr[x].lazy;
tr[x].lazy = 0;
}
if(tr[x].l >= l && tr[x].r <= r) return tr[x].ans;
ans += query(x << 1, l, r);
ans += query(x << 1 | 1, l, r);
return ans;
}
int main() {
int n, m;
cin >> n >> m;
for(int i = 1; i <= n; i++) {
scanf("%lld", &e[i]);
}
build(1, 1, n);
while(m--) {
int a, b, d; LL c;
scanf("%d", &d);
if(d == 2) {
scanf("%d%d", &a, &b);
printf("%lld\n", query(1, a, b));
} else {
scanf("%d%d%lld", &a, &b, &c);
modify(1, a, b, c);
}
}
return 0;
}5.其他例题
2023年3月14日修订
【例题2】洛谷P3373 【模板】线段树 2
题目链接如下:
P3373 【模板】线段树 2 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
题目描述
如题,已知一个数列,你需要进行下面三种操作:
- 将某区间每一个数乘上 $x$
- 将某区间每一个数加上 $x$
- 求出某区间每一个数的和
输入格式
第一行包含三个整数 $n,m,p$,分别表示该数列数字的个数、操作的总个数和模数。
第二行包含 $n$ 个用空格分隔的整数,其中第 $i$ 个数字表示数列第 $i$ 项的初始值。
接下来 $m$ 行每行包含若干个整数,表示一个操作,具体如下:
操作 $1$: 格式:1 x y k 含义:将区间 $[x,y]$ 内每个数乘上 $k$
操作 $2$: 格式:2 x y k 含义:将区间 $[x,y]$ 内每个数加上 $k$
操作 $3$: 格式:3 x y 含义:输出区间 $[x,y]$ 内每个数的和对 $p$ 取模所得的结果
输出格式
输出包含若干行整数,即为所有操作 $3$ 的结果。
样例 #1
样例输入 #1
5 5 38
1 5 4 2 3
2 1 4 1
3 2 5
1 2 4 2
2 3 5 5
3 1 4样例输出 #1
17
2提示
【数据范围】
对于 $30\%$ 的数据:$n \le 8$,$m \le 10$
对于 $70\%$ 的数据:$n \le 10^3 $,$ m \le 10^4$
对于 $100\%$ 的数据:$ n \le 10^5$,$ m \le 10^5$
除样例外,$p = 571373$
(数据已经过加强^\_^)
样例说明:
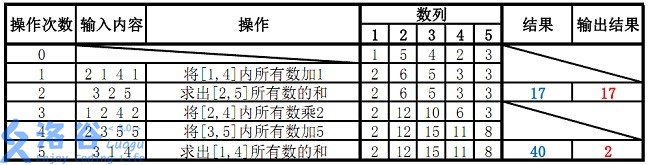
故输出应为 $17$、$2$( $40 \bmod 38 = 2$ )
【例题2】题目解析与代码
我用的方法还是懒标记在原地激活的方法(具体见第四章),也就是拥有懒标记的结点并没有被激活过。
本题的难点在于两个懒标记的先后加载顺序,以及它们之间会发生的影响。
那么这里存在一个问题就是如果我有加法标记后再次加上乘法标记需要怎么操作:我们需要对加法标记乘以相同的乘法数值才行。
而且激活的时候必须先激活乘法标记再激活加法标记(因为我们激活的顺序影响了儿子结点的懒标记更改顺序)
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
int MOD = 571373;
struct Tree{
int l, r;
//mul是乘法标记,它的初始值为1,add是加法标记,它的初始值为0
LL ans, add = 0, mul = 1;
}tr[N * 6];
int n, m;
void build(int x, int l, int r) {
tr[x].l = l; tr[x].r = r;
if(l == r) {
scanf("%lld", &tr[x].ans);
return;
}
int mid = l + r >> 1;
build(x << 1, l, mid);
build(x << 1 | 1, mid + 1, r);
tr[x].ans = (tr[x << 1].ans + tr[x << 1 | 1].ans) % MOD;
}
void modify(int x, int l, int r, LL k, int way) {
//注意这里是先激活乘的后激活加的,顺序不可改变
//因为子树如果原来存在add标记,那么它必须先乘mul标记
//注意子树的mul是相乘的
if(tr[x].mul != 1) {
tr[x].ans = (tr[x].ans * tr[x].mul) % MOD;
tr[x << 1].add = (tr[x << 1].add * tr[x].mul) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add * tr[x].mul) % MOD;
tr[x << 1].mul = (tr[x << 1].mul * tr[x].mul) % MOD;
tr[x << 1 | 1].mul = (tr[x << 1 | 1].mul * tr[x].mul) % MOD;
tr[x].mul = 1;
}
//必须后激活add的标记
if(tr[x].add) {
tr[x].ans = (tr[x].ans + (((tr[x].r - tr[x].l + 1) * tr[x].add) % MOD)) % MOD;
tr[x << 1].add = (tr[x << 1].add + tr[x].add) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add + tr[x].add) % MOD;
tr[x].add = 0;
}
if(tr[x].l > r || tr[x].r < l) return;
if(tr[x].l >= l && tr[x].r <= r) {
if(way == 2) {
tr[x].ans = (tr[x].ans + (((tr[x].r - tr[x].l + 1) * k) % MOD)) % MOD;
tr[x << 1].add = (tr[x << 1].add + k) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add + k) % MOD;
} else {
tr[x].ans = (tr[x].ans * k) % MOD;
//子树如果存在add标记,那么必须乘这个下发的值
tr[x << 1].add = (tr[x << 1].add * k) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add * k) % MOD;
tr[x << 1].mul = (tr[x << 1].mul * k) % MOD;
tr[x << 1 | 1].mul = (tr[x << 1 | 1].mul * k) % MOD;
}
return;
}
modify(x << 1, l, r, k, way);
modify(x << 1 | 1, l, r, k, way);
tr[x].ans = (tr[x << 1].ans + tr[x << 1 | 1].ans) % MOD;
}
LL query(int x, int l, int r) {
LL ans = 0;
if(tr[x].mul != 1) {
tr[x].ans = (tr[x].ans * tr[x].mul) % MOD;
tr[x << 1].add = (tr[x << 1].add * tr[x].mul) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add * tr[x].mul) % MOD;
tr[x << 1].mul = (tr[x << 1].mul * tr[x].mul) % MOD;
tr[x << 1 | 1].mul = (tr[x << 1 | 1].mul * tr[x].mul) % MOD;
tr[x].mul = 1;
}
if(tr[x].add) {
tr[x].ans = (tr[x].ans + (((tr[x].r - tr[x].l + 1) * tr[x].add) % MOD)) % MOD;
tr[x << 1].add = (tr[x << 1].add + tr[x].add) % MOD;
tr[x << 1 | 1].add = (tr[x << 1 | 1].add + tr[x].add) % MOD;
tr[x].add = 0;
}
if(tr[x].l > r || tr[x].r < l) return 0;
if(tr[x].l >= l && tr[x].r <= r) return tr[x].ans;
ans = (ans + query(x << 1, l, r)) % MOD;
ans = (ans + query(x << 1 | 1, l, r)) % MOD;
return ans;
}
int main() {
cin >> n >> m >> MOD;
int t, a, b; LL c;
build(1, 1, n);
while(m--) {
scanf("%d", &t);
if(t == 1 || t == 2) {
scanf("%d%d%lld", &a, &b, &c);
modify(1, a, b, c, t);
}else {
scanf("%d%d", &a, &b);
printf("%d\n", (query(1, a, b) % MOD));
}
}
return 0;
}